
Software-Entwicklung: Benutzerorientierte Analyse großer hochdimensionaler Datenbestände
- type: internship
- semester: WS 15/16
- lecturer:
Benutzerorientierte Analyse großer, hochdimensionaler Datenbestände
Bis 2020 soll die Menge an Daten, die erstellt und konsumiert werden, bei etwa 40 Zetabytes liegen. Die Daten kommen aus sehr verschiedenen Quellen, beispielsweise Sensoren in Maschinen, Überwachungskameras, Nutzer sozialer Netzwerke, E-Mails oder intelligente Stromzähler. Es entstehen in kürzester Zeit Unmengen hochdimensionaler Daten, d. h. von Datenobjekten mit sehr vielen Attributen, die analysiert werden müssen. In vielen Fällen sind Daten nach ihrer Erfassung aber auch schnell veraltet. In diesem Praktikum sind deshalb sogenannte Datenströme Gegenstand der Betrachtung.
Es existiert bereits eine Vielfalt von Verfahren für die Analyse von Datenströmen (inklusive Implementierungen), z. B. für die Erkennung von (neu entstandenen) Korrelationen von Datenströmen, univariate und multivariate Change Detection, das Erkennen von Ballungen und Ausreißern (Cluster und Outlier).
Derartige Verfahren generieren zu jeder Zeit neue Erkenntnisse aus den Datenströme und passen das vorhandene Wissen kontinuierlich an die neuen Daten an.
Eine geeignete Darstellung der Analyseergebnisse ermöglicht jetzt sogenanntes kooperatives Data Mining, d. h. der Benutzer steuert die Datenanalyse, indem er mit dem zugrunde liegenden System interagiert.
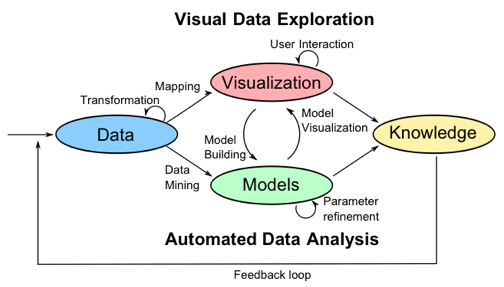
[Keim et al 2010]: Mastering The Information Age - Solving Problems with Visual Analytics
In diesem Praktikum geht es also nicht nur darum, dem Benutzer interessante Ergebnisse jener Algorithmen möglichst in Echtzeit zu präsentieren, sondern ihm auch die Möglichkeit zu geben, aus Anwendersicht Feedback zu geben, in für ihn komfortabler Weise. Beispiele für Feedback im vorliegenden Kontext sind:
- „Dieser Ausreißer ist – für mich als Anwender – interessant, ich will auf mehr Ausreißer dieser Art hingewiesen werden.“
- „Dieses Datenobjekt ist aus meiner Perspektive als Anwender kein Ausreißer.“
- „Dieses Muster ist interessant, die konkreten Attribute jedoch nicht.“
In der Abbildung oben entspricht dies dem Pfeil ‚User Interaction‘.
Dieses Feedback wird dann an die Algorithmen weitergegeben (Pfeil ‚Model Building‘ von ‚Visualization‘ zu ‚Models‘), die in Zukunft dann (hoffentlich) Ergebnisse generieren werden, die besser zu den Informationsbedürfnissen des Anwenders passen, der das System gerade benutzt. Die allermeisten Algorithmen haben Parametereinstellungen, auf die das Feedback dann abgebildet werden kann.
Aufgabe:
Ziel dieses PSE-Projektes ist es, eine intuitive Benutzeroberfläche für Data Mining Algorithmen für Datenströme mit Interaktionsmöglichkeiten zu entwerfen und zu implementieren. Implementierungen jener Algorithmen werden wir zur Verfügung stellen.
Dies beinhaltet:
- Sie überlegen sich, wie sich die Vielfalt der Ergebnisse unterschiedlicher Analysealgorithmen auf einem Bildschirm sinnvoll darstellen lässt. Die Art der Visualisierung an sich muss nicht innovativ sein; herkömmliche Darstellungen sind ausreichend.
- Sie machen sich vertraut mit den Arten von Auffälligkeiten, die die angesprochenen Algorithmen finden können (nicht jedoch mit der Arbeitsweise dieser Verfahren).
- Sie überlegen sich, wie sinnvolles Feedback aus Anwendersicht aussehen könnte.
- Sie konzipieren und realisieren für wenige ausgewählte Fälle (die Sie selbst bestimmen können) Lösungen, die das Feedback auf die Parameter/Schnittstellen der Analysealgorithmen abbilden. (Qualitätsexperimente, d. h. wie gut ist Ihre Abbildung, würden den Rahmen dieses PSE-Projekts sprengen und werden von Ihnen ebenfalls nicht verlangt.)
Die umgesetzte Software-Infrastruktur wollen wir insbesondere bei der Durchführung von Forschungsexperimenten mit verschiedenen Parametern und Bedingungen einsetzen. Daher steht die Entwicklung einer modular gestalteten Lösung mit einer gewissen Flexibilität und einfacher Erweiterbarkeit im Vordergrund. Sollten Sie diese Aufgabe bearbeiten wollen, bitten wir Sie, im Anschluss Ihre Lösung unter einer nichtrestriktiven Software-Lizenz frei verfügbar zu machen.