
Improving Semantic Change Analysis by Combining Word Embeddings and Word Frequencies
-
Autor:
Adrian Englhardt, Jens Willkomm, Martin Schäler, Klemens Böhm
-
Quelle:
International Journal on Digital Libraries (2020). DOI: 10.1007/s00799-019-00271-6
- Datum: 20.05.2019
-
 This is the supplementary material for the article "Improving Semantic Change Analysis by Combining Word Embeddings and Word Frequencies"
This is the supplementary material for the article "Improving Semantic Change Analysis by Combining Word Embeddings and Word Frequencies"Abstract Language is constantly evolving. As part of diachronic linguistics, semantic change analysis examines how the meanings of words evolve over time. Such semantic awareness is important for web search, to adapt to recent hypes or trends. Recent research on semantic change analysis relying on word embeddings has yielded significant improvements over previous work. However, a recent, but somewhat neglected observation so far is that the rate of semantic shift negatively correlates with word-usage frequency. In this article, we therefore propose SCAF, Semantic Change Analysis with Frequency. It abstracts from the concrete embeddings and includes word frequencies as an orthogonal feature. SCAF allows using different combinations of embedding type, optimization algorithm and alignment method. Additionally, we leverage existing approaches for time series analysis, by using change detection methods to identify semantic shifts. In an evaluation with a realistic setup, SCAF achieves better detection rates than prior approaches, 95% instead of 51%. On the Google Books Ngram data set, our approach detects both known as well as yet unknown shifts for popular words.
Supplementary Material
Source Code
Embedding models
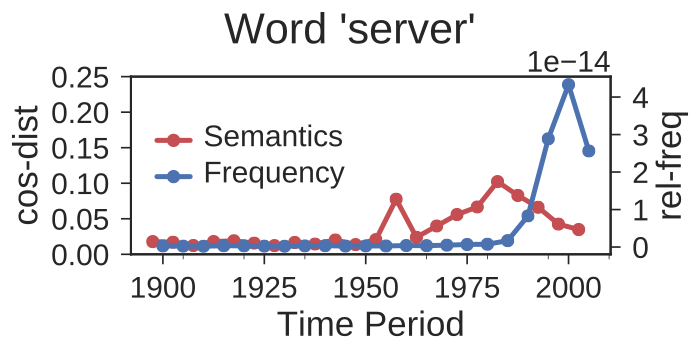
The following tables contain the embeddings used in Section 5.2 and 5.3. The perturbation list of the (donor, receptor) pairs is available here.
| Alignment | CBHS | SGHS | CBNS | SGNS |
|---|---|---|---|---|
| None | [6.0 GB] | [5.9 GB] | [5.9 GB] | [5.8 GB] |
| Incremental Training | [6.0 GB] | [5.9 GB] | [6.1 GB] | [6.0 GB] |
| Alignment | CBHS | SGHS | CBNS | SGNS |
|---|---|---|---|---|
| None | [4.6 GB] | [5.0 GB] | ||
| Incremental Training | [5.0 GB] | [5.0 GB] | [4.9 GB] | [5.0 GB] |
The embeddings for the Twitter dataset (Section 5.4) with incrementally trained SGNS are available here: [3.1 GB]
The embedding models are licensed under a Creative Commons Attribution 4.0 International License. If you use these models in your scientific work, please reference the companion paper.