
Dieser Zusammenschrieb geht davon aus, dass Sie mit sehr elementaren Prinzipien der Spieltheorie,so wie sie z. B. hier beschrieben sind, in etwa vertraut sind. Ggf. sollten Sie diesen Text oder eine andere kurze Einführung lesen, bevor Sie weiterlesen.
- Gegenstand der Betrachtung im Folgenden sind wiederholte Spiele („repeated games“).
- Ihre Aufgabe besteht verkürzt darin, einen Simulator für wiederholte Spiele zu entwerfen und zu implementieren.
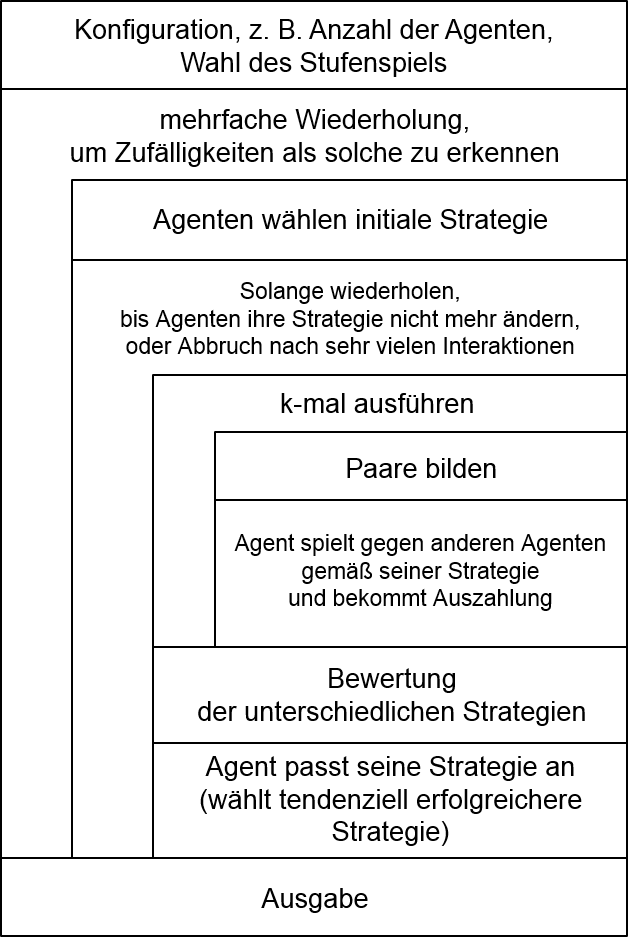
- Die Abbildung zeigt den Ablauf, der diesem Simulator zugrunde liegt – die folgende Beschreibung des Struktogramms beginnt ‚in der Mitte‘:
- Eine Folge bestehend aus ‚Paare bilden‘ und ‚Agent spielt ...‘ bezeichnen wir als Runde.
- Die Simulation betrachtet eine bestimmte (vorab festgelegte) Zahl von Agenten; die Aktion ‚Paare bilden‘ fasst je zwei Agenten zu einem Paar zusammen. Es gibt mehrere Möglichkeiten (die Ihre Implementierung auch berücksichtigen soll), wie das geschehen kann: Die einfachste Variante ist, dass Agenten zufällig gepaart werden. Eine Alternative besteht darin, dass Agenten explizit sagen können, mit welchen anderen Agenten sie ein Paar bilden wollen, und die Aktion ‚Paare bilden‘ berücksichtigt das dann so gut wie möglich. (Dazu später mehr.)
- ‚Agent spielt ...‘ bedeutet, dass jeder Agent mit seinem gerade ermittelten Paar-Partner das zugrunde liegende elementare Spiel, also z. B. das Gefangenendilemma, das Diktator-Spiel usw. einmal gemäß seiner aktuellen Strategie spielt. In der Spieltheorie-Literatur heißt dieses zugrunde liegende Spiel auch Stufenspiel. Hier ist eine Liste möglicher Stufenspiele. Bei vielen Stufenspielen, z. B. beim Gefangenendilemma, gibt es eine kooperative und eine unkooperative Handlungsoption. Jeder Agent hat eine Strategie, aus der sich seine Handlung ergibt. Beispiele für Strategien sind tit-for-tat oder grim. Bei tit-for-tat ist der Agent kooperativ genau dann, wenn der andere Agent in der vorigen Runde kooperativ war. Bei grim ist der Agent kooperativ genau dann, wenn der andere Agent in allen vorigen Runden kooperativ war. Die Strategie eines Agenten kann sich im Laufe der Zeit ändern, dazu gleich mehr.
- Diese Abfolge wird k-mal wiederholt. k ist eine große Zahl, damit das System sich einschwingen kann. Die Agenten tun so, als sei der Wert von k nicht bekannt. (Wäre er bekannt, gäbe es hier unerwünschte sogenannte ‚end game effects‘', d. h. dass ein Agent gegen Ende plötzlich unkooperativ wird, um sich noch rasch einen Vorteil zu verschaffen.)
- Nach k Runden wird betrachtet, welche Strategien wie erfolgreich waren. Agenten mit einer wenig erfolgreichen Strategie wechseln für die nächsten k Runden mit einer gewissen Wahrscheinlichkeit zu einer erfolgreicheren Strategie. (Wie genau dieses Wechseln ausgestaltet sein soll, habe ich mir noch nicht überlegt – eventuell kann ein genetischer Algorithmus hier zur Anwendung kommen.)
- Es gibt Anlass zur Erwartung, dass diese Abfolge (Agenten treten gegeneinander an, und erfolgreichere Strategien kommen mit der Zeit häufiger zur Anwendung) in vielen Fällen zu einem Gleichgewicht führt, d. h. alle Agenten behalten ihre jeweilige Strategie bei, weil sie bei einem Wechsel keine Verbesserung erwarten können. Das System gibt dann die Strategien der Agenten in diesem Gleichgewichtszustand aus.
- Beim zu entwickelnden Simulator gibt es jetzt einen wesentlichen Unterschied zu herkömmlichen wiederholten Spielen. Bei herkömmlichen wiederholten Spielen wollen Spieler ihre Auszahlungen maximieren: Hier hingegen haben Spieler das Ziel, eine Auszahlung zu bekommen, die größer ist als die möglichst vieler anderer Spieler. Umgangssprachlich ausgedrückt, ist ein Spieler umso zufriedener, desto höher sein Rang ist, d. h. desto mehr Spieler, was die Summe der Auszahlungen angeht, er hinter sich gelassen hat; der absolute Auszahlungsbetrag spielt aber keine Rolle. – Aus wissenschaftlicher Sicht interessiert mich, inwieweit diese andere, nichtkonventionelle, tendenziell auf weniger Kooperation zielende Zielsetzung zu anderen Gleichgewichtszuständen/zu anderen Strategien, die Agenten in Gleichgewichtszuständen verfolgen, führt als die herkömmliche Zielsetzung. Meine Erwartung ist, von Ihnen ein Werkzeug zu bekommen, mit dem ich das mit Hilfe von Simulationen untersuchen kann.
{kind=link}
Es folgen weitere Erläuterungen zur Aufgabenstellung/zum angestrebten Software-Produkt:
- Die vergangenen Handlungen aller Agenten sind bekannt, ebenso die Summe der Auszahlungen, die ein Agent in den Runden bis zum aktuellen Zeitpunkt erhalten hat (und somit auch sein aktueller Rang). Strategien, die diese Information benötigen, z. B. Tit-for-Tat, sind also möglich.
- Wir sehen mehrere Möglichkeiten, den Erfolg eines Agenten zu quantifizieren – die bisherigen diesbezüglichen Einlassungen waren noch etwas undifferenziert:
- (a) Sortieren der Agenten nach der Summe der in Runden 1, ..., k erhaltenen Auszahlungen; ein Agent ist umso erfolgreicher, je weiter vorne er in dieser Liste steht. D. h. ausschlaggebend ist der Rang am Ende der k Runden
- (b) Das Kriterium ist der durchschnittliche Rang während der k Runden, in etwa wie folgt:
- Grundlage der Berechnung ist ein laufendes Fenster der Größe w, das zum aktuellen Zeitpunkt endet.
- Analog zu (a) berechnen wir den Rang des Agenten (d. h. seine Position in der sortierten Liste) für die letzten w Runden.
- Der Erfolg des Agenten ist der Durchschnittsrang über alle sliding window-Positionen innerhalb der Folge der Länge k. Weitere Möglichkeiten sind denkbar – sich hier etwas zu überlegen, übertrage ich Ihnen. Welche Variante zur Anwendung kommt, ist ein Konfigurationsparameter des anvisierten Systems.
- Der Raum der möglichen Strategien ist breit – hier ist eine (unvollständige) Liste:
- (a) Tit-for-Tat
- (b) Grim
- (c) Kooperation nur mit Agenten, die ungefähr so wohlhabend sind wie ich selbst, ansonsten keine Kooperation
- (d) Tit-for-Tat nur mit Agenten, die ungefähr so wohlhabend sind wie ich selbst, ansonsten keine Kooperation
- (e) Keine Kooperation mit Agenten, die ‚reicher‘ sind als ich, ansonsten Tit-for-Tat
- (f) Wie (e), nur ‚ärmer‘ anstelle von ‚reicher‘
- (g) immer Kooperation
- (h) keine Kooperation
- Hierzu diverse Erläuterungen:
- Diese Liste ist nicht nur unvollständig, sondern auch informell. Es obliegt Ihnen, im Entwurfsdokument die Strategien präzise und eindeutig zu beschreiben.
- Manche Strategien sind offensichtlich parametrisiert; z. B. muss ‚ungefähr so wohlhabend wie ich‘ quantifiziert werden.
- Gemischte Strategien (z. B. ‚mit Wahrscheinlichkeit x Tit-for-Tat, mit Wahrscheinlichkeit 1-x Strategie (d)‘) sind möglich und sollen ebenfalls in die Betrachtung mit einbezogen werden.
- ‚Paare bilden‘ soll die Möglichkeit beinhalten (ebenfalls als Konfigurationsparameter des Systems), dass Agenten explizit angeben können, mit welchen anderen Agenten sie in der nächsten Runde gern gepaart werden möchten. – Genauer:
- Jeder Agent hat ja eine Strategie, gemäß der er in der nächsten Runde mit bestimmten Agenten kooperieren würde, und mit den restlichen Agenten würde er nicht kooperieren. Die Agenten, mit denen der aktuelle Agent kooperieren würde, sind genau die, mit denen er gerne gepaart werden würde.
- Es soll dann ein (möglichst einfacher) Matching-Algorithmus zur Anwendung kommen, der möglichst viele Paare bildet bestehend aus Agenten, die miteinander kooperieren würden. Die restlichen Agenten werden dann zufällig gepaart.
- Es wäre grundsätzlich möglich, dass Agenten unterschiedliche Strategien haben für das Bilden von Paaren sowie, nachdem sie gepaart wurden, für das Stufenspiel. Das würde den Aufbau aber übermäßig kompliziert machen, deshalb eine Strategie für beides.