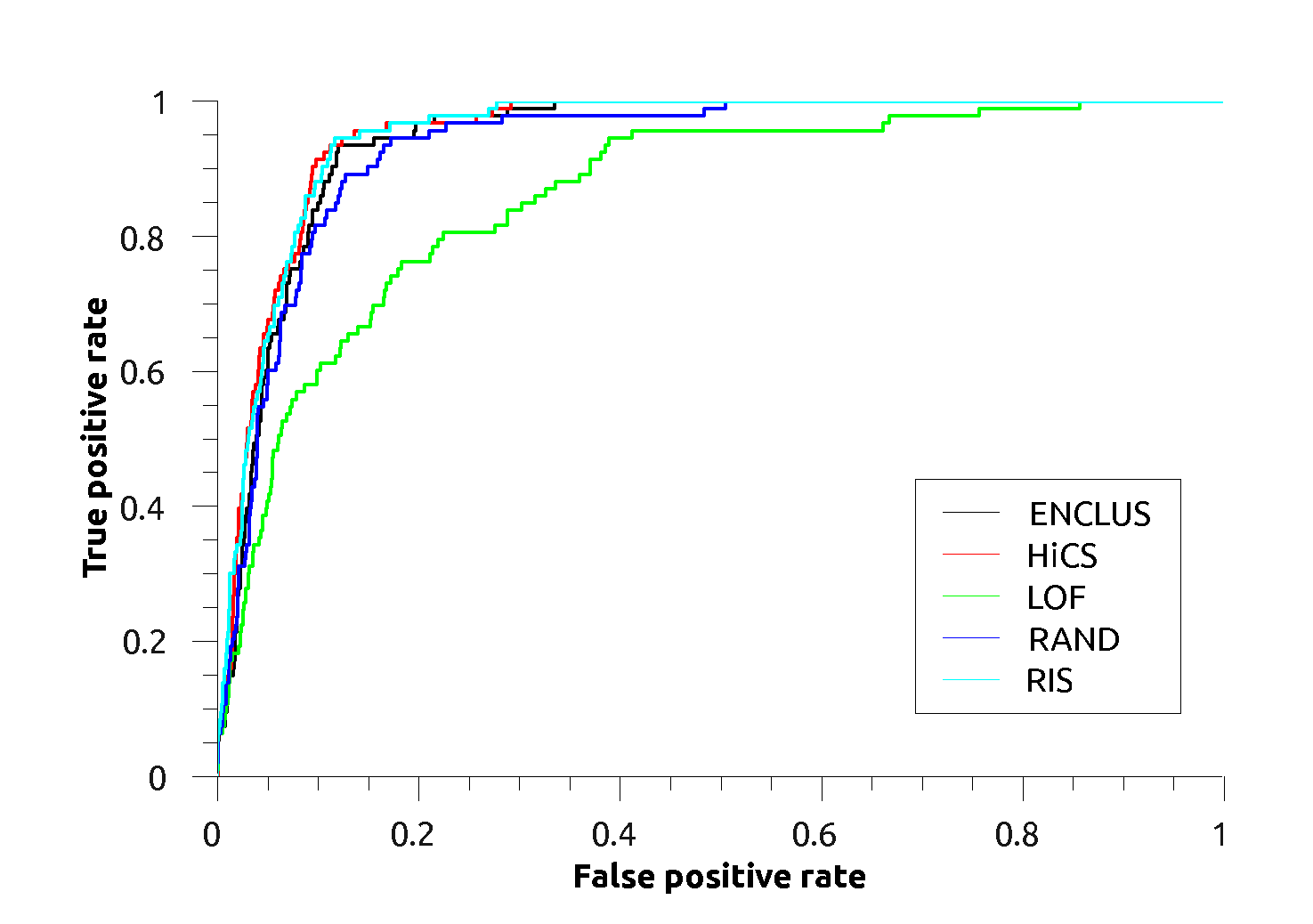
Ann-Thyroid:
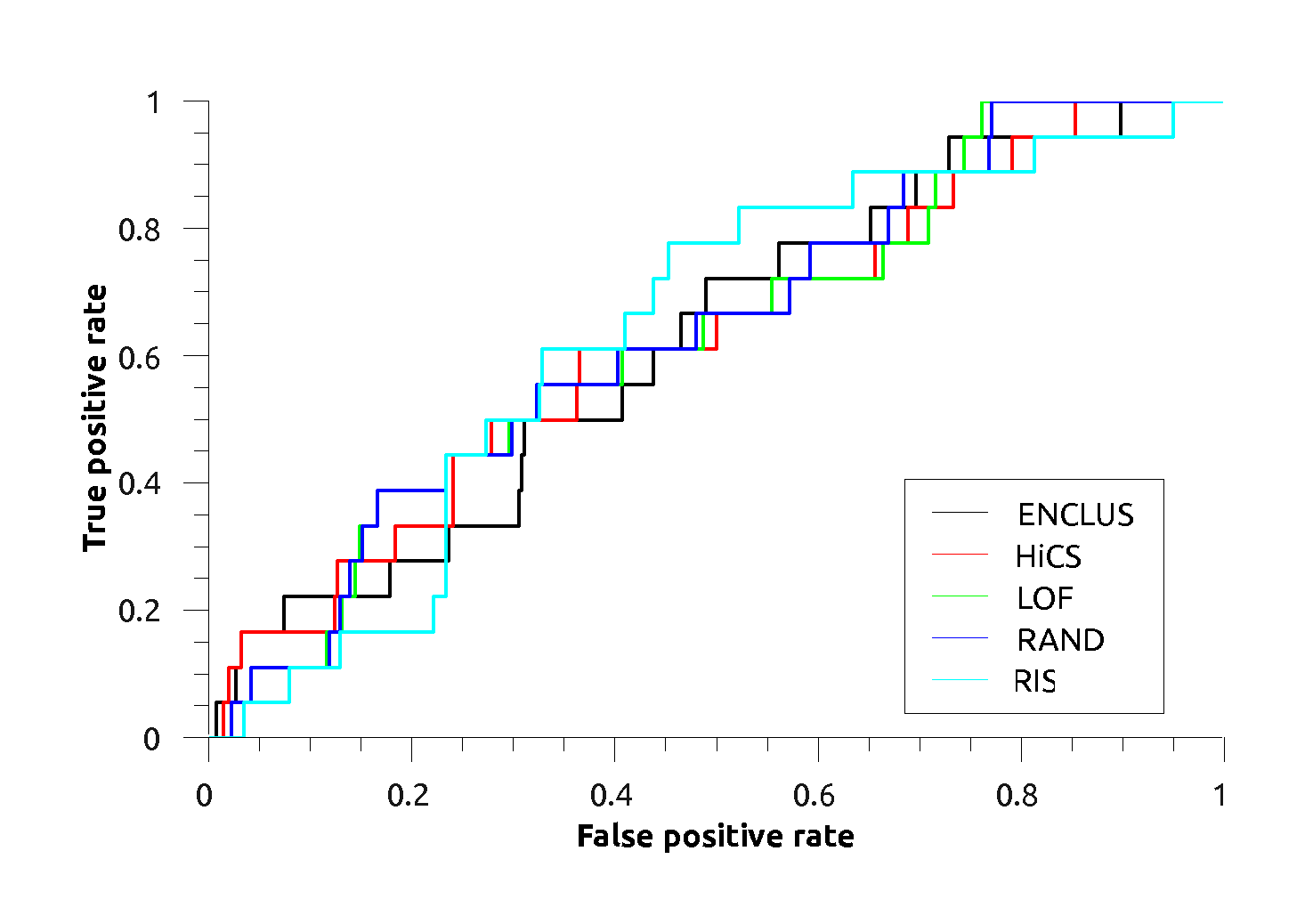
Arrythmia:
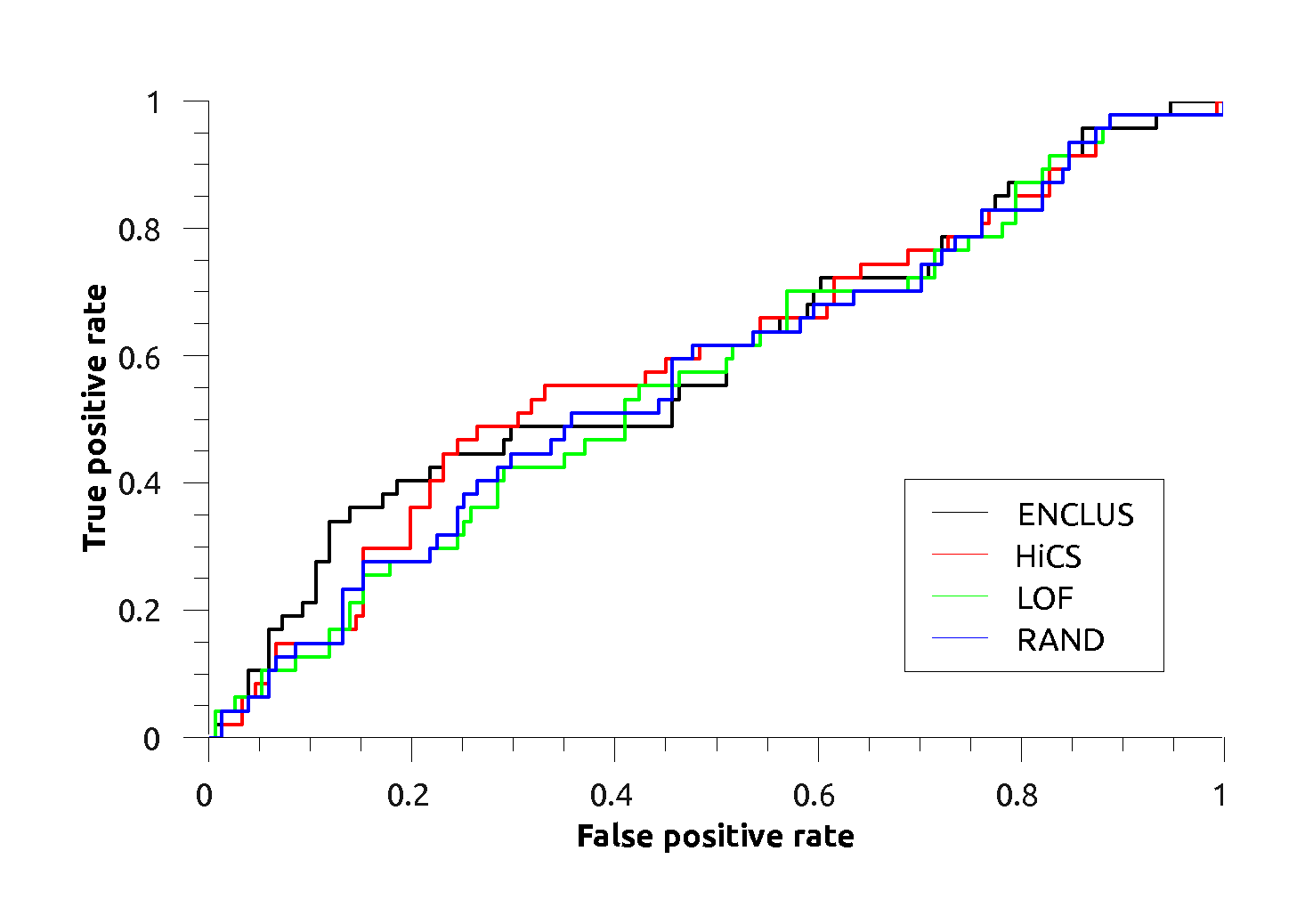
Breast:
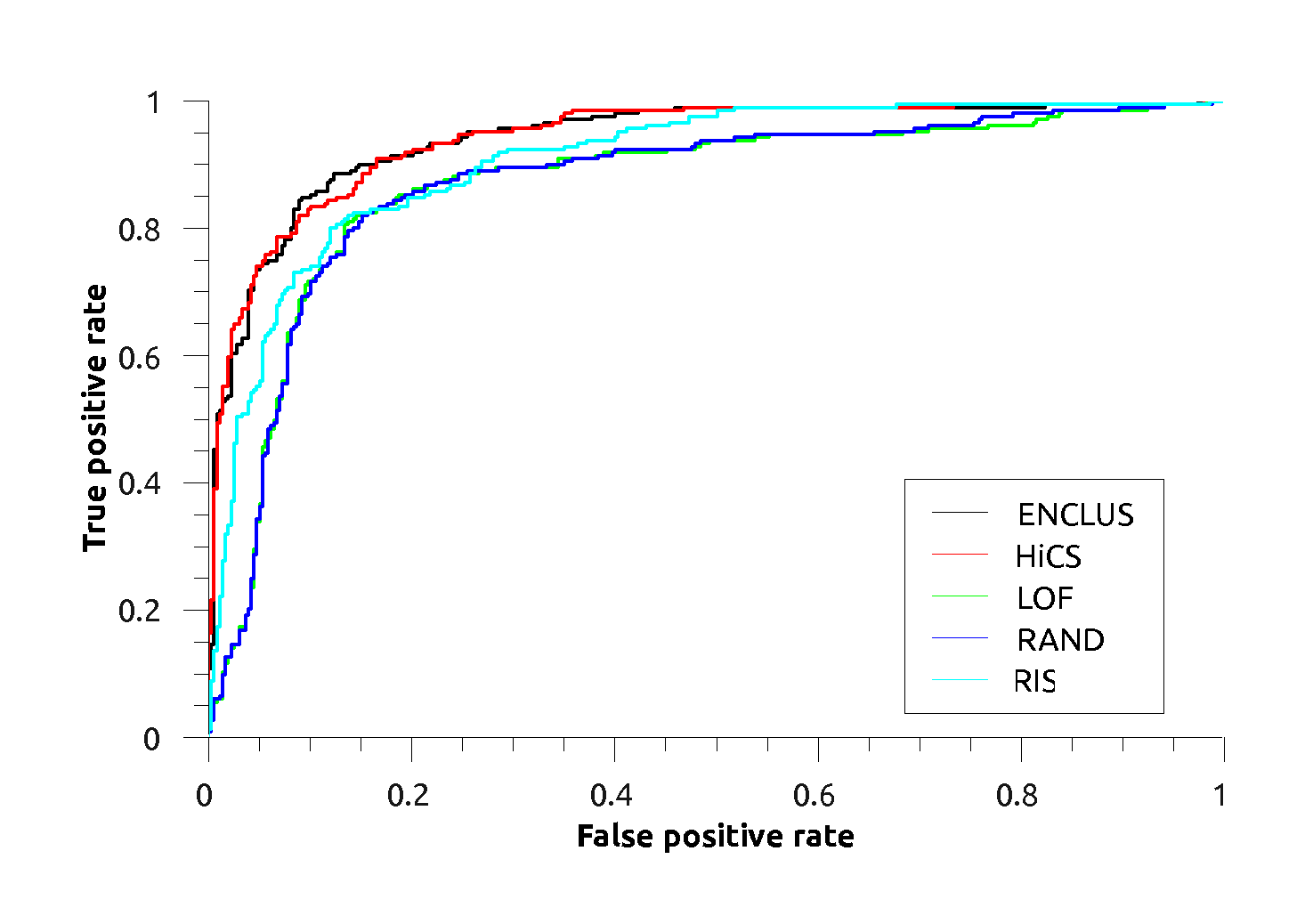
Breast (diagnostic):
Diabetes:
Glass:
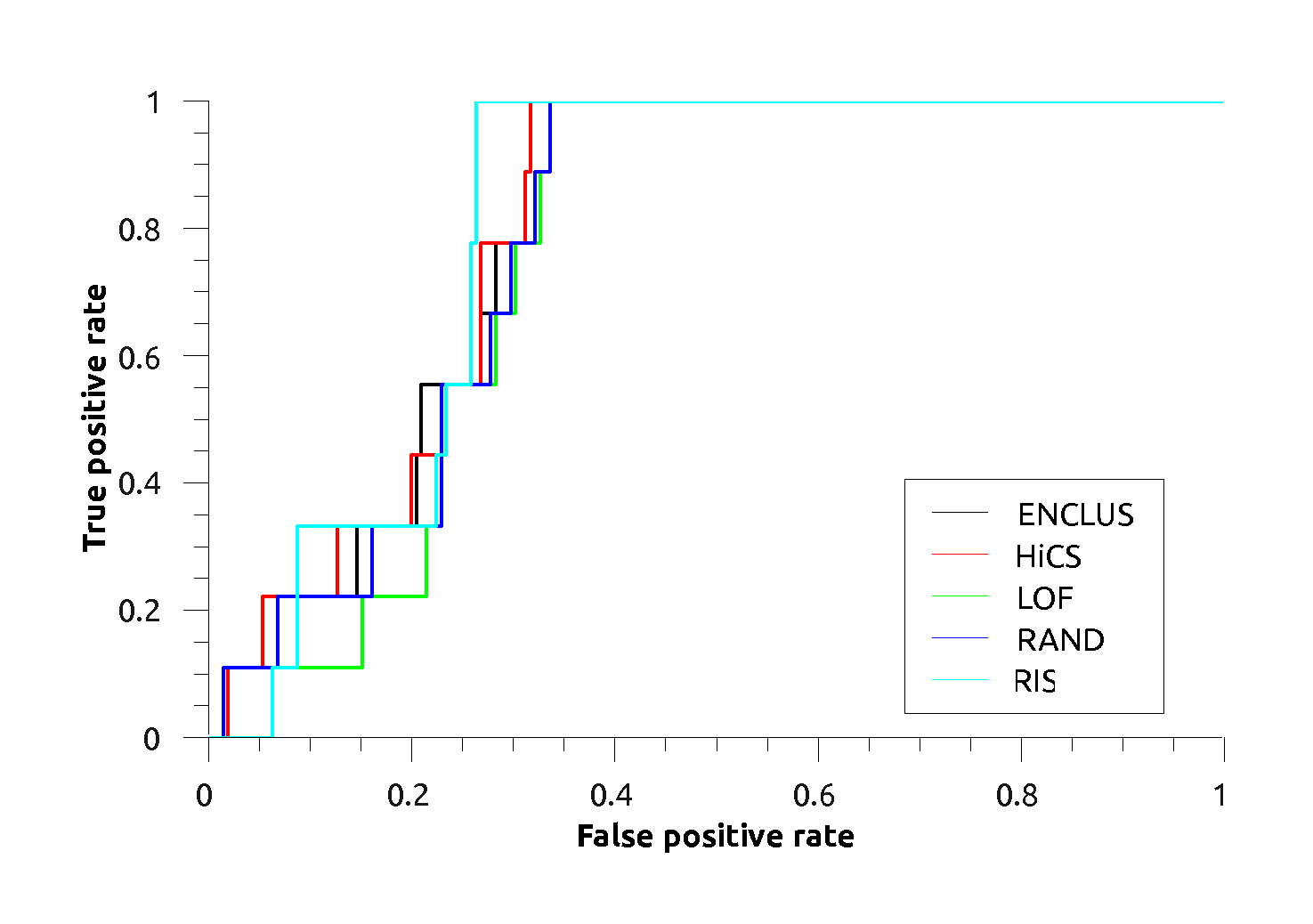
Ionosphere:
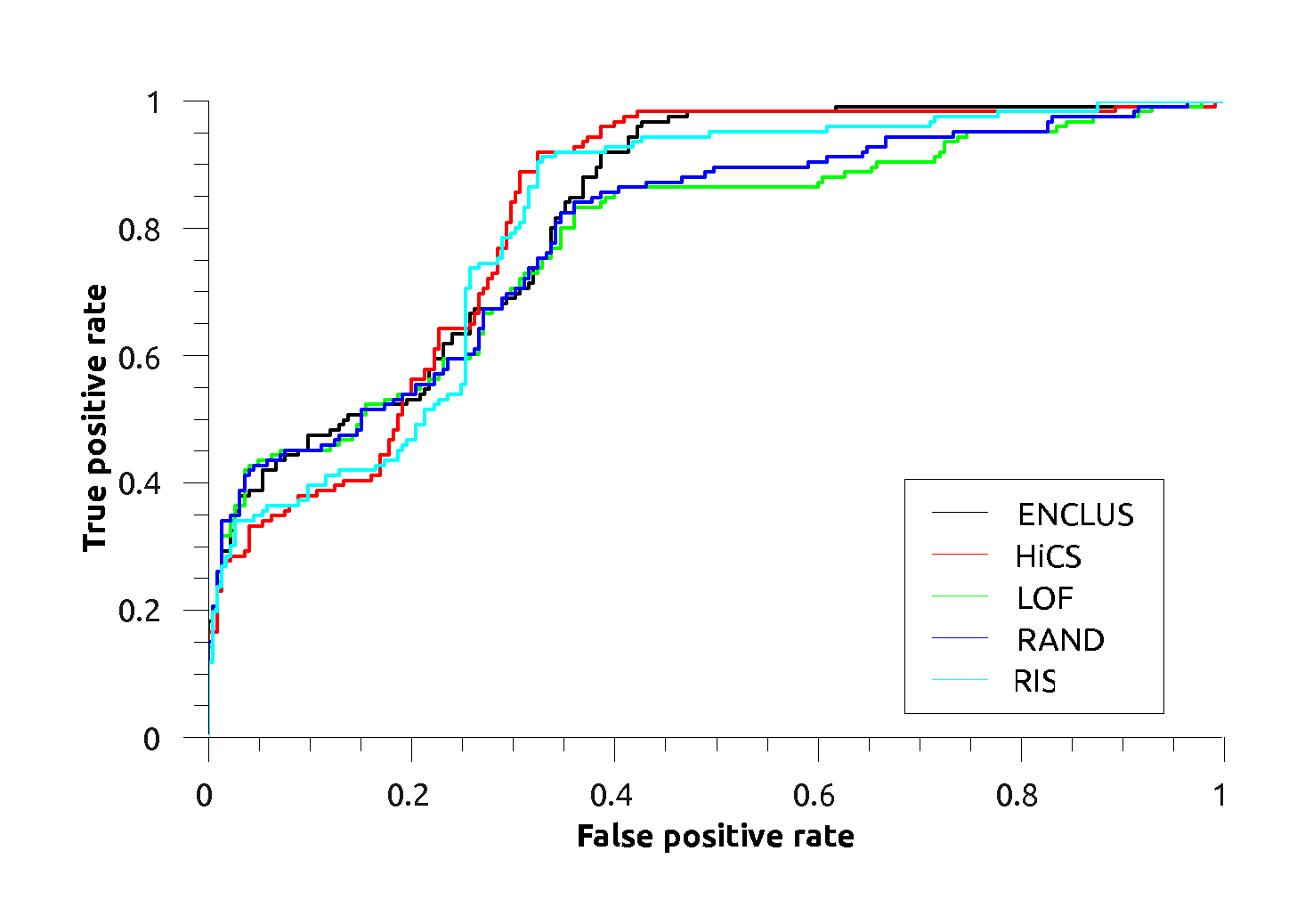
Pendigits:
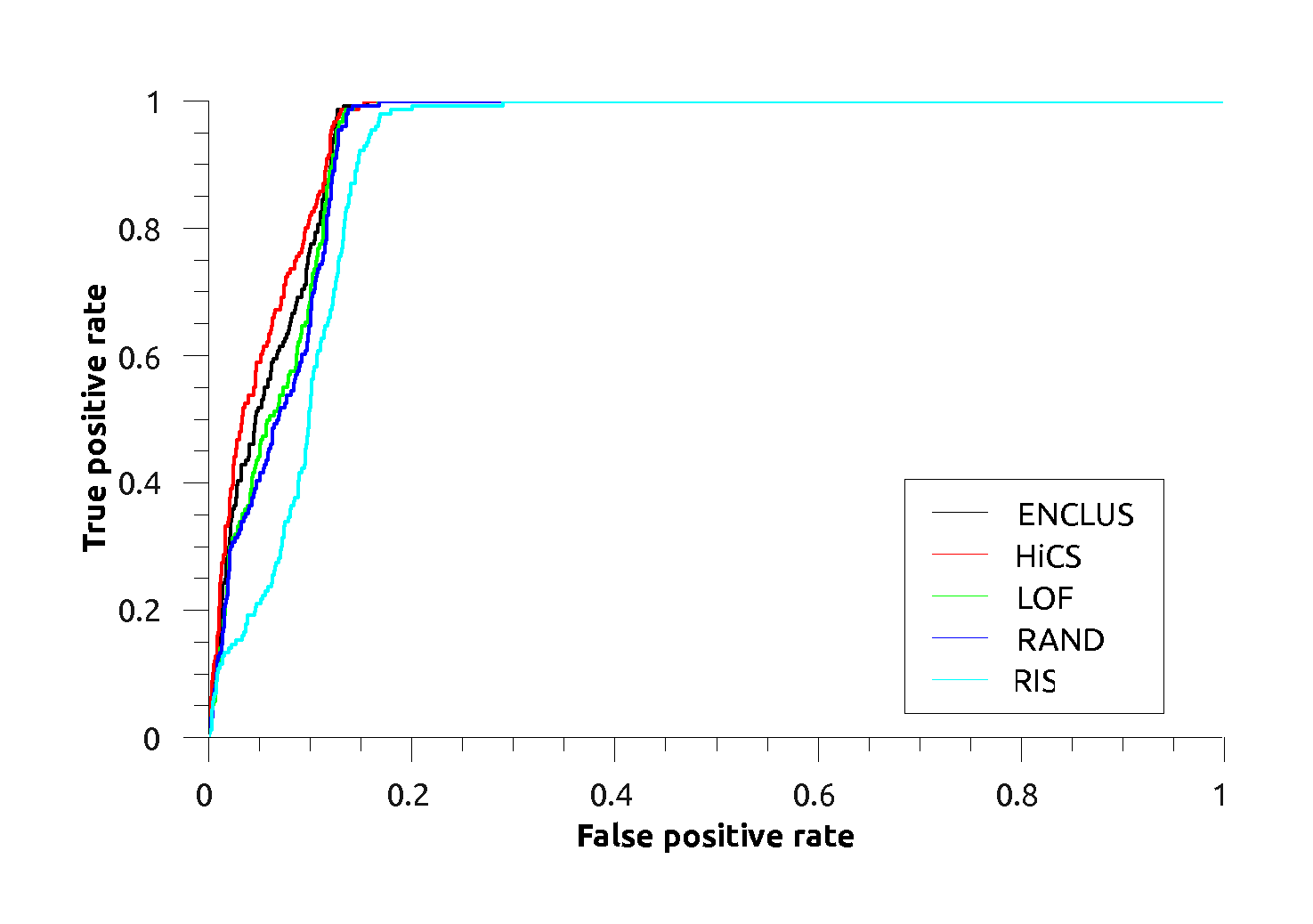
|
Paper ID |
432 |
|
Title |
HiCS: High Contrast Subspaces for Density-Based Outlier Ranking Data |
|
Authors |
Fabian Keller, Emmanuel Müller, Klemens Böhm |
Ann-Thyroid: |
Arrythmia: |
Breast: |
Breast (diagnostic): |
Diabetes: |
Glass: |
Ionosphere: |
Pendigits: |
The reviewer is expected to
agree to confidentiality requirements
with respect to non-disclosure of data on this website, as
the reviewer does for any paper under review. Usage is limited to
repeating and exploring the experimental results of this paper. Until
this work has not been published, no other use is allowed, especially
not for other publications. This website conveniently documents the
experimental setup used in the evaluation described in our manuscript.
We will provide additional experimental data, setup, and software,
which will be made available when the manuscript is published.
After publication of this work, we encourage researchers in this area to use the proposed algorithm for their own publications as competitor. Our implementation will then be available for anyone to use. Thus, all algorithms, data sets and parameter setting will be available for the community.